This article discusses the roles and responsibilities expected of both myself and the entrepreneurs who hire me.
Agile Scrum is the software development framework that is my go-to guide on how to approach the development of software as a freelance programmer. The Scrum framework generally assumes a large team in an enterprise company. It requires modification to apply to freelance work and very small teams.
I'll describe those same roles in this article, but adapt them to the scope of a small, freelance team. The 'team' is usually made up of only me and the entrepreneur hiring me. In this case, I am both the 'Scrum Master' and 'Scrum Team' and they are the 'Product Owner'. The Product Owner has more responsibility than simply writing checks or getting a weekly status update. I wrote this article to communicate the responsibilities that are expected of them when they hire me.
To quickly summarize, here are the expectations I have for each client who hires me:
We meet over Zoom at least once per week, or once every-other week. More often or less often interferes with the output of work.
There are two primary focuses of our meetings:
We work together to write down and document Use Cases, which describe what they want me to build for them.
We review the Implementation Status sections of the Specification documents, so that they understand what the current state of development is for their project.
They interact with the app in-between meetings, and use the meeting to give feedback on what they like and dislike. This is essentially 'quality assurance', and in small teams only the Product Owner can provide this feedback, since it is their vision that we're trying to manifest into reality.
We work together in each meeting to create tasks, and to prioritize which tasks will be worked on before the next meeting. Prioritizing tasks is another critical role that can only be performed by the Product Owner.
As the self-appointed 'Scrum Master', here are the primary responsibilities for that role within the scope of a small freelance team:
I capture the Product Owner's vision of what the product should 'do', by writing a high-level, non-technical description of what they want and putting that into a Use Case document. This ensures we stay aligned on the high-level vision of the product.
I export the ideas in the Use Case document into a series of Specification documents. These are low-level, technical descriptions of how the product will achieve the high level goals in the Use Case documents.
I then generate tasks from the Specification document and assign them to the members of the Scrum Team.
As the Development Team finishes tasks, I update the 'Implementation Status' section of the Specification documents to reflect how closely reality matches the specifications.
In the case of a small project where I am the only freelance developer, I make up the whole Scrum Team. But the beauty of Scrum is that it expands to teams of any size. The members of the Scrum Team are the people with the specific skills to build what is needed. Scrum is used to help the team self-organize.
So when I am a one-man team, I am the one responsible for executing the tasks on the task board. If there are more people on the team, then the tasks will be assigned to different people. Other than that, the process does not change. People can be added or removed from the team at any time, as needed. It's common to add specialists such as graphic designers, front end developers, etc.
This article doesn't discuss programming languages or frameworks. The context of this article covers the workflow and management of building an app. This is based on my experience building both open and closed source apps.
Anyone who has read CashStack.info is familiar with my approach to layered architecture. This mental model applies to many areas of life. Take for instance, the construction of a house:
Each layer supports the layer above it. In the Cash Stack, the app at the top is supported by the 'foundation' of the blockchain:
Because layered approaches are so useful, they are my go-to mental framework for trying to understanding complex systems. The management of app development is a complex system, and I've been thinking about how to represent it in layers. Here is what I've come up with:
At the base of the stack is the Use Case. The use case is a simple document that answers the following questions:
What is the problem your app solves?
Who is the target user for your app?
Describe the 'happy path'. This is the the navigational path and clicks your ideal user takes from start to finish, using the path of least resistance.
Defining the the Use Case is incredibly important. It is the conceptual 'foundation' upon which the rest of the application is built. This is not a technical document. It's a high-level document that is used by management and technical people to collaborate.
For management, the Use Case document describes (in plain English) the high level concepts.
For the technical team, the Use Case dictates the trade-offs that need to be taken when choosing between different technical options, in order to achieve the high level goals described in the Use Case document.
The next layer for effectively managing app development is the Specification. This starts as a single document, but it will usually grow into a collection of documents. The Specification is a plain-English description of all the details of the app. Whereas the Use Case document strives to be high-level, the Specification contains low-level technical details.
Another difference is that the Use Case document is created by management and should not change much with time. If it does, that's the same thing as 'moving the goal posts'. The Use Case is the target that you're trying to hit by executing the software development process. In contrast, the Specification is a living document. It should be updated every week.
Because the Specification is a technical document, it should be formatted using headings, bullet points, and have a table of contents at the top of each document. It should be easy to navigate. This is a reference document that many people will refer to while building the app. I've found it best to write the Specification in Markdown, and keep it in the same code repository with the app. That way the same version-control tools can be applied to the Specification.
At the base of each section describing a major feature, there should be a section entitled Implementation Status. This section should be updated on a weekly basis. Whereas the rest of the Specification document describes how the app should work, the Implemtation Status section captures how the app currently works. This section is one of the primary communication tools between the Product Owner (management & money) and the technical team. The technical lead should update these sections each week before the team meeting. The technical team should review these changes at each weekly meeting.
Task management is concerned with the day-to-day management of the team. The details are captured in the video below, which I've included in previous blog posts.
At the end of the task-management process, there is a 'Done' column. That is where the Task Management layer connects to the Specification layer. When tasks in the 'Done' column are archived, that is the opportunity to update the Implementation Status sections in the Specification document.
That makes sense if you think about it: Tasks are completed in an effort to move the app towards the goals described in the Specification document. Tasks are organized in Sprints, which typically last a week or two. The Specification should be updated at the end of each Sprint, to capture the progress.
The term 'Operations' is synonymous with 'Dev Ops' or 'Infrastructure'. These are the physical computers, domain names, network settings, and open source software that allows things to work. If this infrastructure is not fully functional, it does not matter how beautiful the app is. This is why operations must take priority over Development or QA.
Someone on the team needs to take responsibility for these Dev Ops. It's an important job, and if you do it right, no one will thank you, because everything will 'just work'.
This is a difficult part of the app to manage, because it's easy to forget about... until things break. Scheduling maintenance on a calendar is the best way to manage these tasks. The team should set regular reminders to do pro-active maintenance on any existing infrastructure that they depend on.
Development is the process described in this previous blog post. While this section is managed through Task Management, it is executed by following the path described in that blog post.
Quality Assurance (QA) is a continuous on-going effort. It's never 'done'. It's also not appropriate to worry about, until the Development process has code in production. There are many steps of development that need to take place before it's appropriate to start worrying about QA.
From a technical standpoint, managing QA comes back to managing the Specification document. As new Use Cases are developed, new code will be written, and Specification documents will be updated. QA is the process of ensuring the code running in Production meets the goals described in the Specification Document.
There are other aspects of QA that are non-technical: interfacing with users and discovering new pain points. But that is largely outside the scope of the process described here.
To ground me when one of my software projects feels like it's going off the rails. This article is a mental-map of my well-traversed terrain. I use it to orient and ground myself.
To set expectations with my clients. This article allows me to share my mental-map with those who hire me, to better communicate how I think about their project, and how I plan to approach it.
Briefly, here are the major phases of my development process:
One big reason is for the sake of semantics. The software development industry is full of buzz words and jargon. What I call my 'software development process' is closer to what Wikipedia identifies as Systems Development Life Cycle than their article on Software Development Process. The meaning of these words are important when I'm managing junior developers or communicating with a client.
Another reason is my specialty within the software development world. I'm generally a freelancer, but sometimes I work with or manage a small team. Occasionally I will work for a large company, but that is the exception rather than the rule. I also work primarily with open source software.
These experiences have led me to diverge from the textbook examples of software development, like Waterfall or Agile Scum, which are designed for use in a conventional, large company. I wear all the hats when I work as a lone freelancer. As the team expands, I delegate the hats, but the overall process doesn't change. Even within the scope of a more rigid process like Scrum, my development process doesn't really change. The same things need to happen, regardless of what they are called. So words are important, but also not.
Finally, another big reason for me to write down my process is to provide a conceptual exit ramp for my clients. I seem to have the same conversations over-and-over with clients, around our software development process. This usually stems from bad expectations, which developed in the 90s.
In the 90s, Microsoft made a bunch of money from putting software onto disks, putting those disks into a box, and then selling the box. Anything resembling upgrades or maintenance was an opportunity to put more stuff into boxes and make more money. But software isn't like that any more, because most software today is built on top of open source code. Today, building software is like buying a puppy.
I haven't always started with writing a specification, but the more experience I gain, the more valuable this process becomes. Five years ago, I didn't have enough experience to be very good at writing specifications. That's what it takes: experience. Now that I've taken several project from conception to production, and I'm aware of common patterns in that process, I can write specifications. If you don't have that experience, it's still an important process to go through.
"Fake it till you make it" applies here. The reason is that a specification should be the first document created and the last document edited. It changes over time, as new information about the project comes to light. Version control is important though, so that everyone involved can easily look back and identify when the goal posts get moved.
The purpose of writing a specification is to get the important engineering ideas down on paper. This allows the lead developer, the money people, and everyone else to stay on the same page. Often I will break this up into two sections:
An Architecture document will explain the high-level architecture.
The Specification document will explain the low-level details of the data structures, file layout, and User workflow.
Here are some of the questions I try to answer with these documents:
Who is the end user?
What are they trying achieve with the software?
More specifically, what is the problem the User is trying to solve by using the software?
What other software or network resources does this app depend on?
What are the data structures used by the software?
What are the major sub-components of the app and how do they work?
See my Clean Architecture post, as it applies to this phase of the development process.
Here are examples of specifications that I've written and maintain:
I use the words Prototype and Proof of Concept (PoC) interchangeably. The focus of this phase is to prove that the software can actually achieve the goals set out in the Specification; not every little detail, but the major sub-components of the architecture.
Processes like Scrum and Test Driven Development (TDD) never mention this important phase of software development, because they do not apply here. In this phase I write quick and dirty code. Most of it will get thrown away or heavily refactored. The Prototyping phase is the most creative and 'fun' part of the software development process. The goal is not to write maintainable code. The outcome is binary: Can it be built or not?
This is an important phase for a few reasons:
This phase is all about quick discovery of obstacles and potential pitfalls.
It provides quick feedback to investors and management. If the team can't deliver, then everyone can save a lot of money, time, and emotions by identifying it as early as possible.
While this process can be humbling, it's incredibly educational for the developers involved.
This phase revolves around the idea of the 'happy path'. The happy path is the path of least resistance from the Users standpoint. It's the path they take from start to finish, assuming everything goes right.
That's when you know you're done with this phase of the development process. A developer (not a normal user) can create a video recording of them going through the happy path.
Finally we're at the software development phase where frameworks like Scrum and Test Driven Development (TDD) apply. This is the most well-studied part of the software development process.
This is the phase where work can be created and divvied up among team members, or not. I created this video to show how I manage this phase of work with small, remote teams:
The Production phase has everything to do with maintenance. The buzzword for this phase is Continuous Integration and Continuous Delivery (CI/CD). Production is the process of iterating through this workflow:
Identify a new issue or feature.
Fix the issue or add the feature. This code goes into a development branch.
Code review and QA is conducted before merging the change into production.
Release a new version.
Start from the beginning on the next feature or issue.
The main difference between the Development and Production phases is sustainability. During development, the product is not 'done', so it's not expected to generate a cash flow. In Production, there is the assumption that the software is mature and is on a trajectory to generating a cash flow. Remember, building software is like buying a puppy. If you can't pay to feed your puppy (generating a cash flow), then your puppy will die from starvation.
I'm a huge fan of Test Driven Development (TDD). The Development and Production phases of software development is where TDD really shines
Some past clients have expressed unpleasant surprise that I save the Design phase for last. Many want to start with design first, but that is a mistake. Form follows function. Starting with sexy graphics and visually-appealing-but-nonfunctional mock-ups is a great way to waste money and get a project stuck, in my experience.
"Make it work, then make it fast, then make it pretty."
I've adopted the pragmatic approach of the quote above.
Making it work, means making it work reliably. That's the most difficult step, and one that many entrepreneurs take for granted. This is the step that is far harder and more expensive than anyone thinks it will be.
Once reliability is achieved, it's then time to focus on the user experience. That means making it fast, but also convenient.
Finally, and not before, it's time to think about perception and beauty. If an app does not work, it doesn't matter how sexy it looks. But an ugly app, which works reliably, will get used. And that usage can generate a cash flow. With a cash flow, all other things are possible.
I also should point out here that I do not do design work. If a client is insistent on having a custom visual design, I insist that they hire a designer. Visual design is not in my field of expertise, and I try to be very clear about that.
I use Bootstrap when building a new app. It takes care of all the visual design, and ensures that the app looks good on both a phone and a desktop. With Bootstrap, all I need to focus on is stacking blocks and making them do stuff.
I've never seen anyone else present the software development process quite the way I have here. But my process is based on hard-won experience.
If you are a senior developer, or a manager of software development teams, and you'd like to reach out, contact me via Twitter or Telegram. I'm keen to learn from other's experiences and to refine my own understanding of this great art form we call software development.
If you are an entrepreneur looking for someone to help you develop your next great idea, I'm for hire! I can help you architect your idea, find inexpensive remote developers, and manage those developers for you. Here are the details.
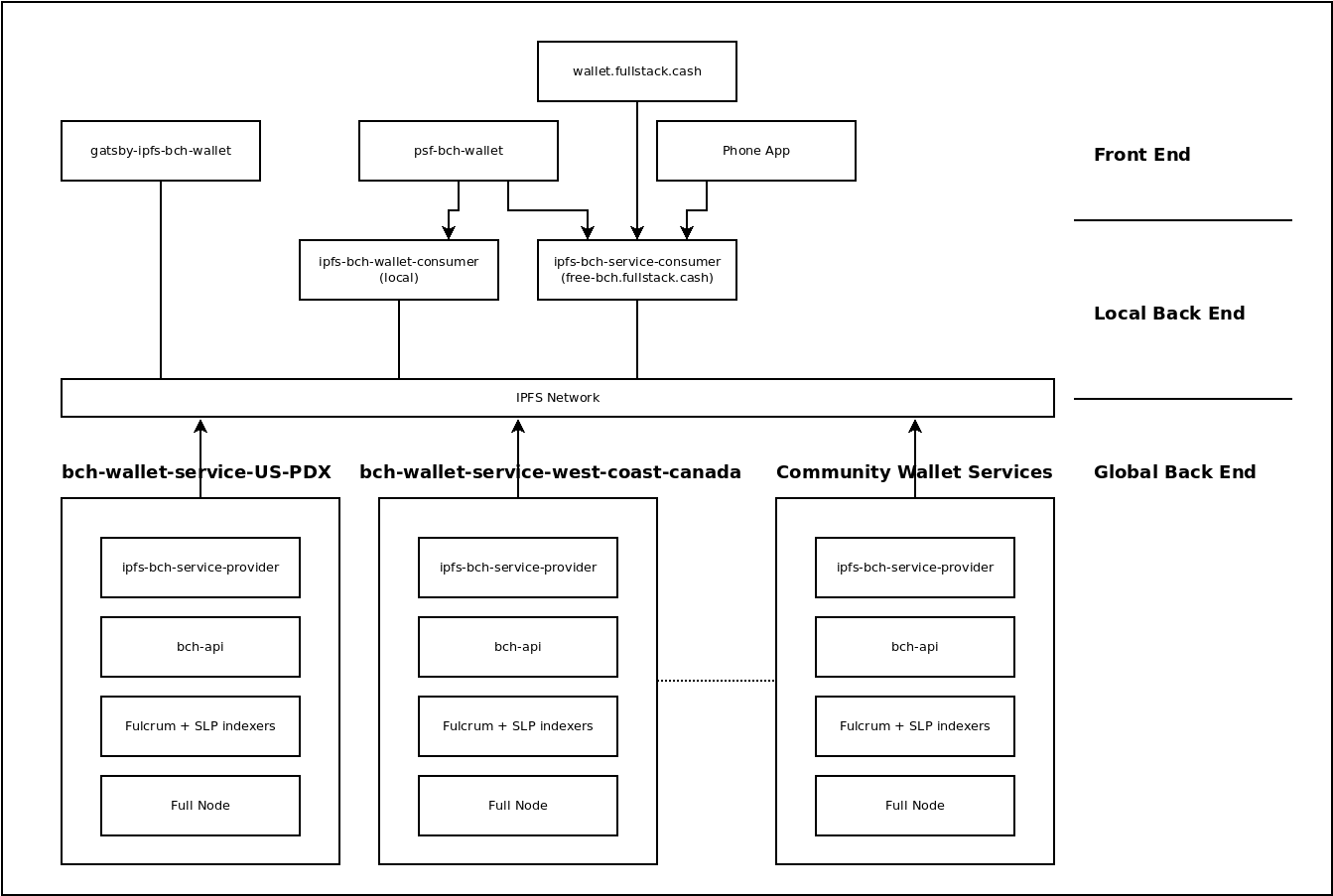
The previous blog post provided a very high-level overview of the Web 3 Cash Stack architecture. This article descends into various implementations of that architecture that I, and other decentralized members of the PSF, are in the process of standing up.
If the images appear too small to read the text, click on them to open a larger version of the image.
While it looks lot busier, the image above has all all the same features as the simplified Web 3 diagram in the previous blog post. It's easier to describe how all the pieces fit together by walking through the three main layers of infrastructure:
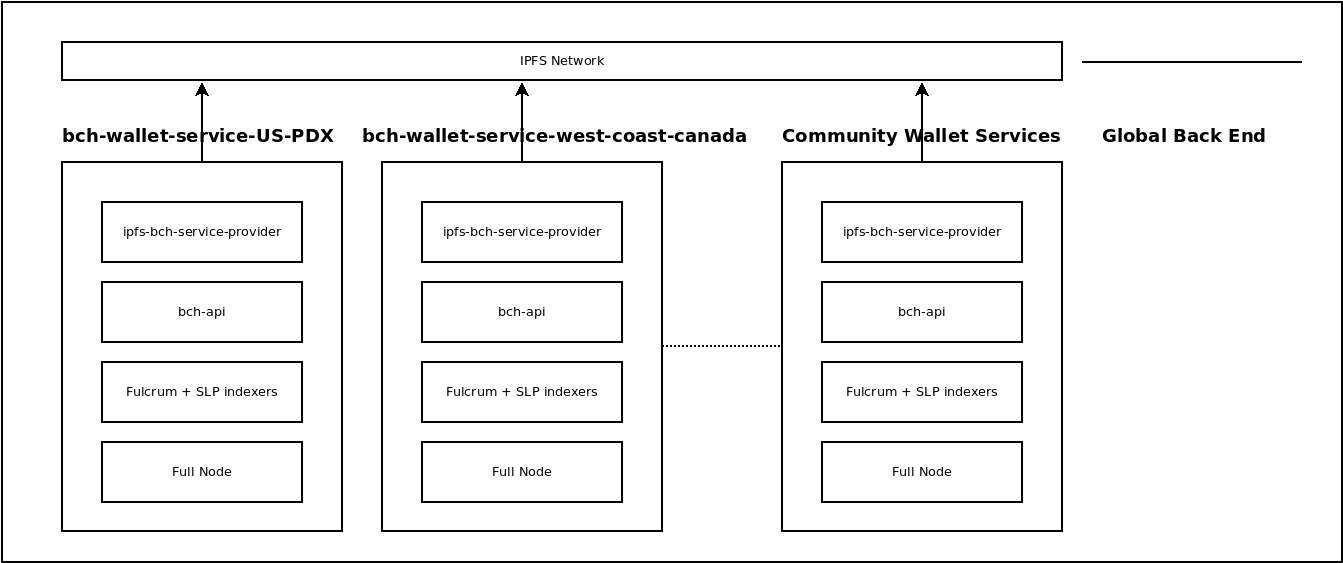
The global back end is the part of the software stack that has changed the least. While the original Cash Stack has had steady improvements, it's basic architecture has changed very little in the last three years. What has changed is the emphasis on software further up the stack that interfaces with it, and putting the JSON RPC over IPFS on equal footing with the conventional REST API.
Whereas the focus has been on bch-api in the past, there is a new focus on the ipfs-bch-wallet-service as the primary way to interface with the back end infrastructure. bch-api, our Web 2.0 workhorse, isn't going anywhere. It's flexible and high-resolution REST API interface will always be preferred for Web 2.0 companies and exchanges. ipfs-bch-wallet-service compliements bch-api by simplifying the API to a few endpoints that are needed for common wallet use cases. It also provides this API over two interfaces:
REST API over HTTP
JSON RPC over IPFS
The JSON RPC over IPFS is what unlocks the real power of web3. Because IPFS automatically handles the networking and easily penetrates firewalls, the global back end software can use consumer hard drives, in normal desktop computers, using home internet connections. This directly competes with the cloud infrastructure needed by Web 2.0 apps, and drastically lowers costs. It also makes it easier for web3 community members to support one another, and improves decentralization.
In the image, two PSF servers are called out by their ipfs-coord names:
bch-wallet-service-US-PDX
bch-wallet-service-west-coast-canada
There are more than these two servers on the network, and more will be added in the future thanks to PSF bounties. Because these back end servers are interchangeable, the software higher up in the stack can choose one-of-many in order to achieve its goals. They all connect to a common 'bus', which is a subnetwork on IPFS, created by the ipfs-coord library.
The JSON RPC over IPFS interface lowers costs, improves decentralization, and improves reliability.
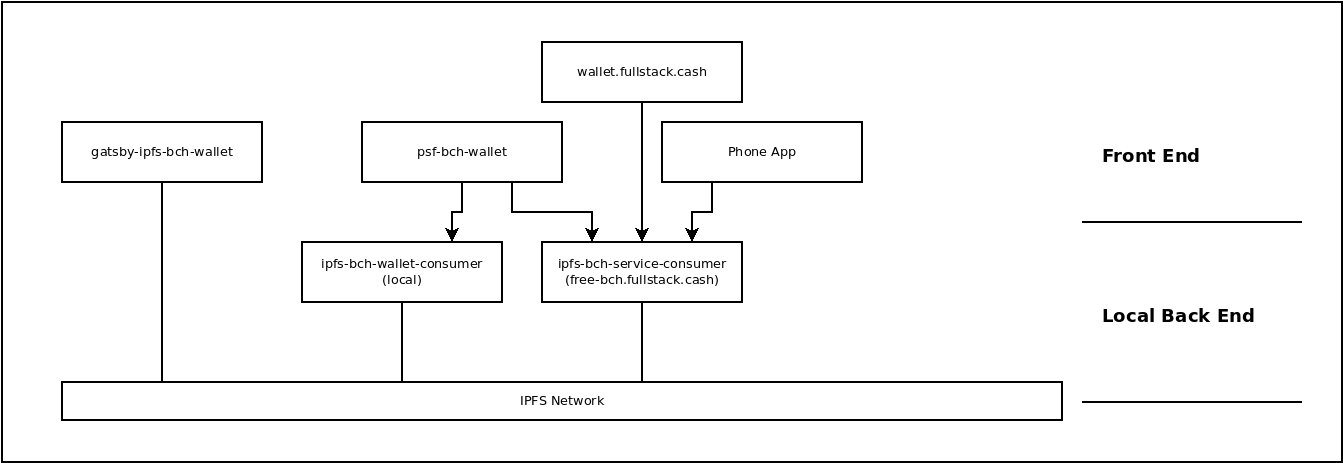
The concept of a 'local' back end is a new concept introduced in the web3 Cash Stack architecture, and it's largely encompassed by a single piece of software: ipfs-bch-wallet-consumer. This is the mirror image of ipfs-bch-wallet-service.
Compared to the Global Back End, ipfs-bch-wallet-consumer is a very 'light' piece of software. It can run comfortably on low-power computing devices, like the Pi 400, with a minimal internet connection.
Eventually, ipfs-bch-wallet-consumer will automatically find and connect to the lowest-latency wallet service it can find on the IPFS network. All communication between the two pieces of software is end-to-end encrypted.
ipfs-bch-wallet-consumer provides a convenient, local REST API interface for programmers to develop against. This allows experienced Web 2.0 developers to leverage IPFS without needing to know anything about it or changing their workflow in any way. This single REST API interface is the only 'back end' software a front end developer needs to run.
An instance of ipfs-bch-wallet-consumer is made available as a public API at free-bch.FullStack.cash. This allows public access to the BCH blockchain for phone apps, random web apps, and the psf-bch-wallet command line wallet.
Those four use cases are represented by the four front end software instances in the image below.
wallet.fullstack.cash is a great example of a Web 2.0 app that an Exchange or Company might build. It follows all the Web 2.0 best practices for scaling and a good user experience. This app connects to a cloud-hosted instance of ipfs-bch-wallet-consumer which in-turn connects to a dedicated instance of ipfs-bch-wallet-service. The use of IPFS in this case is superfluous to normal operation, but it does provide a way to 'fall-back' to the community infrastructure in an emergency. A form of 'failing gracefully'.
Up to this point, the PSF has not offered an Android or iOS version of wallet.fullstack.cash because the cloud infrastructure cost is much more expensive. Freeloaders of the REST API service can be avoided in the web app, but not in the phone app. But that is no longer a significant burden with this new architecture.
The phone app represents the 'Casual User' use case. An Android APK file will be offered soon that can be side-loaded to a phone. It will connect to free-bch.fullstack.cash for it's back end infrastructure. That server will load-balance connections between community 'global back ends'. The UX and performance of the app will depend on the community that supports it, and the burden will not be born by a single individual or company.
psf-bch-wallet is a command-line wallet app for Hobby Developers. Because it does not have a graphical user interface, it's much faster and easier to prototype new ideas and compose 'exotic' transactions. This app can connect to free-bch.fullstack.cash for it's back end, but is most flexible when using a local instance of ipfs-bch-wallet-consumer. It has commands to control the IPFS node inside ipfs-bch-wallet-consumer, to make it switch between different back end services. It gives the user complete control over their network connection.
gatsby-ipfs-web-wallet will soon be getting renamed to gatsby-ipfs-bch-wallet. This will be our IPFS-first wallet. The concept of IPFS-first is taken from the 'mobile-first' design philosophy, which took the emphasis off of desktops and moved it to smart phones. In the same way, IPFS-first takes the emphasis off the centralized REST API over HTTP, and moves it to the decentralized JSON RPC over IPFS.
This web wallet will be loaded from Filecoin, and be accessible from any IPFS-gateway, just like this blognp. It will load an IPFS node within the browser-based app, and connect to an instance of ipfs-bch-wallet-serverice directly. Because the app is so self-contained within IPFS, it will be difficult if not impossible to censor. It will be slower than wallet.fullstack.cash, but it should provide wallet accessibility to people in repressive countries that actively try to block their citizens from accessing the blockchain. This will cator to the Censored User use case.
There are many interpretations of Web 3, but a common thread in all of them is an emphasis on re-decentralizing the web. Web 1.0 was very decentralized. Web 2.0 was centralized. Web 3.0 will be re-decentralized.
In early 2021, I started to earnestly dig into the inner workings of IPFS, to answer one burning question: "What is the best way to decentralized back-end infrastructure?"
This blog is an example of a decentralized front-end app, delivered over IPFS, hosted on the Filecoin blockchain. That's great for a blog or a publisher. But to do really sophisticated business applications requires censorship-resistant access to databases, blockchains, and other back-end infrastructure. IPFS API was my first attempt to conceptualize how to wire back-end infrastructure over IPFS. Over the last year I've developed, configured, and re-configured the code and networking behind the Cash Stack in an attempt to find the best configuration.
This blog post summarizes my findings. It's my attempt to describe the path before me, the path I think that lies before the entire blockchain industry. Censorship is coming, and only the decentralized projects will survive. The Use Cases and software architecture in this post provide a map for projects to build a durable foundation of infrastructure.
Before discussing the How, let me present the Why. I was trained to always remember the 'User Story' or the 'Use Case'. Why am I building what I'm building? What problem is it trying to solve? That's what the Use Case captures. Users that want to access blockchain infrastructure can be categorized into one of the following use cases:
Based on my research over the course of 2021, I will discuss different configurations of the Cash Stack. The first configuration uses strictly Web 2.0 principles. The other configuration blends in components that involve IPFS. Which configuration is appropriate, depends on the Use Case being considered.
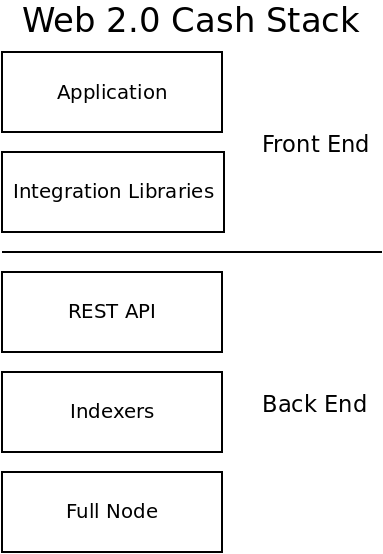
Below is the 'Web 2.0' version described in this Cash Stack post. The centralized architecture is far more efficient and scalable than any 'Web 3.0' or decentralized architecture. It gave birth to the Saas Business Model. As far as blockchain is concerned, this architecture is the most appropriate for the Exchange use case. If there is an Exchange (or company) willing to pay the bills, they can financially sustain the preferred user experience (UX) of the Casual User use case.
The achilles heel of this model is censorship. It's fragile in the face of any censorship. There are well-established industry best practices for censoring this architecture. This architecture is not appropriate for the Censored User use case.
This architecture is also expensive. It's not practical to run this architecture from a home server. Cloud infrastructure is required in all but the most exceptional of cases. Cloud infrastructure has a monthly cost. Stop paying and the infrastructure disappears like smoke. Hobby Developers may be able to run this infrastructure at home, but they can not break out of the hobby-category without funding.
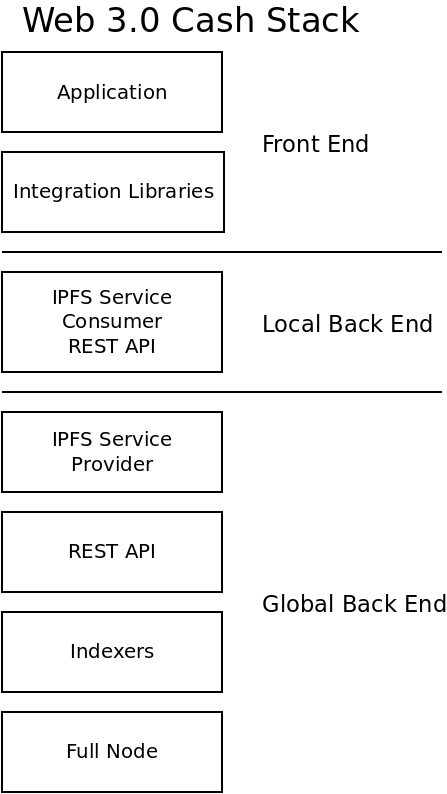
The Web 3.0 Cash Stack inserts two new blocks into the middle of the stack, which are mirror images of one another:
IPFS Service Provider - Proxies the REST API over IPFS.
IPFS Service Consumer - Proxies IPFS communication to a 'local' REST API.
By adding these two new pieces of software, it decouples the expensive 'global' back end infrastructure, and proxies it to a much less expensive 'local' back end REST API. This has several advantages:
Because IPFS automatically handles the complex networking, it's much more pragmatic to run the expensive global back end infrastructure from a home internet connection. This reduces the greatest cost of the Web 2.0 model.
By leveraging Circuit Relays, this architecture is extremely resistant to attempts at censorship.
Because of the decoupling, the local back end is capable of using one-of-many instances of the global back end. It only needs to connect to one in order to succeed, and it can choose any instance on the network.
If implemented correctly, the performance should be acceptable to the Casual User use case. The extra layers adds some latency, but it provides much lower cost. Weather this architecture is appropriate for the Casual User use case depends on the specific application, but the trade-offs may be acceptable. If there is no company to pay for web 2.0 architecture, this web 3.0 architecture may be the only financially practical way to roll out an app for Casual Users.
This architecture really exceeds at the Hobby Developer and Censored User use cases. It should be noted that the 'local' REST API can be embedded entirely in a web browser. This allows Censored Users the convenience of loading an IPFS-based web page in their browser, to achieve the ability to circumvent whatever actor is attempting to censor them.
This is the most flexible architecture for the Hobby Developer. Developers unfamiliar with running back end infrastructure, who want to focus primarily on front end applications, can run a single, simple app to provide the local back end. Developers more comfortable with Dev Ops and running back end infrastructure, can provide the global back end infrastructure to the rest of the community, from the comfort (and cost-savings) of their own home. The Permissionless Software Foundation is offering Bounties to incentivize hobby developers to run this global back end infrastructure.
The descriptions above are abstract. This section is for developers that want to know the specific software implementing the architecture. The software running the Web 2.0 architecture is documented in this Cash Stack post. Here is the new software implementing the Web 3.0 architecture:
ipfs-bch-wallet-service sits at the top of the global back end. It connects to bch-api, or to the infrastructure at FullStack.cash, and it proxies it over IPFS using a JSON RPC interface.
ipfs-bch-wallet-consumer is the mirror image of ipfs-bch-wallet-service. They communicate over IPFS, and ipfs-bch-wallet-consumer provides local REST API endpoints for the front end to interact with.
ipfs-coord is a core library used by both of the above software projects. This allows IPFS nodes to find one another, circumvent firewalls, stay connected, and communicate securely.
minimal-slp-wallet is a JavaScript library that provides basic Bitcoin Cash wallet functionality. It can interface with a local instance of ipfs-bch-wallet-consumer via its REST API. This library is used by gatsby-theme-bch-wallet which you can interact with at wallet.fullstack.cash.
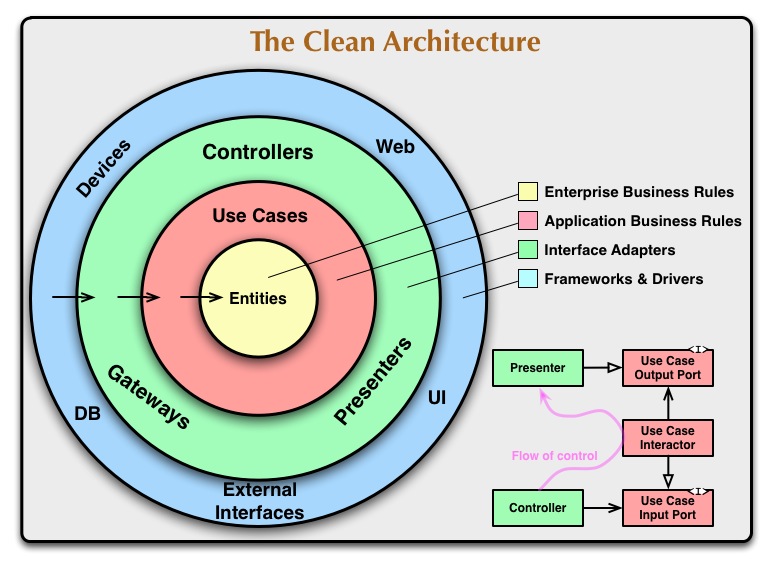
Clean Architecture is a software design pattern created by 'Uncle Bob'. There are two main advantages to using this design pattern:
It manages increasing complexity as new features and interfaces are added over time.
It provides defense against code rot by isolating the parts that rarely change from the parts that change frequently.
I ran across this great video by Bill Sourour applying the Clean Architecture concepts to a REST API server built using node.js and the Express framework. After studying it for some time, I adapted the design patterns in that video and applied them to the P2WDB and the ipfs-service-provider repositories.
In this video, I expand on the Bill's original video and show how I applied Clean Architecture to my own REST API server using the Koa framework.
Code is split up into four groups:
Entities
Use Cases
Adapters
Controllers
Without knowing the patterns and reasoning behind Clean Architecture, the code will look 'weird' to most JavaScript developers. This is because Clean Architecture comes from outside the JavaScript world and some of it's core ideas (like dependency inversion) don't translate easily into JavaScript.
The code in the src folder of this repository is split up into four main directories: entities, use-cases, adapaters, and controllers. These directories reflect the arrangement of concerns in the Clean Architecture diagram:
The above diagram is reflected in the code. The Controllers and Adapters both make up the green circle. I distinguish between the two:
Controllers are inputs that cause the app to react.
Adapters are outputs that the app manipulates, like a database.
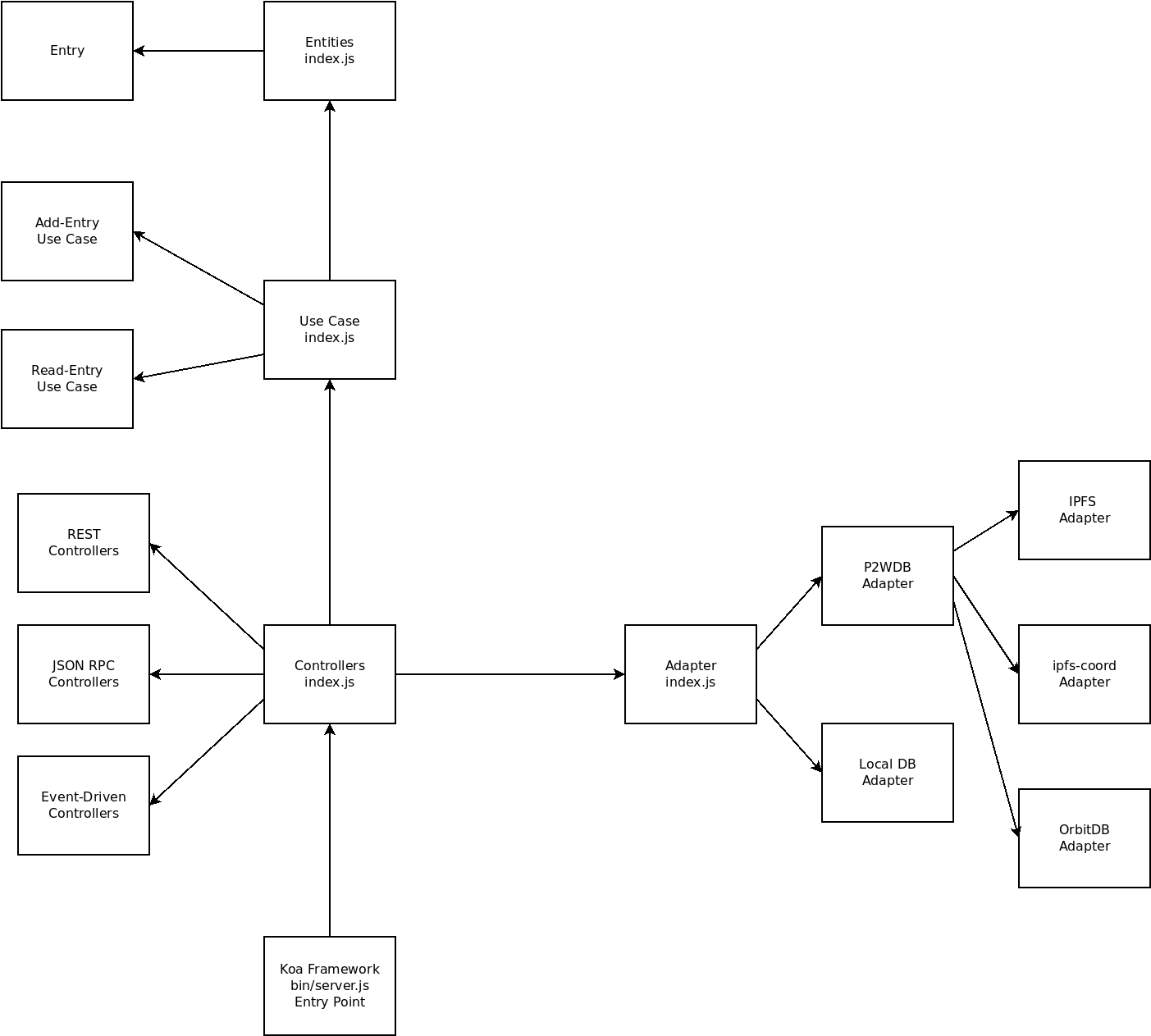
The diagram below shows how dependencies are arranged in the P2WDB project:
Major features of the diagram above:
The blunt point of an arrow connects the file that depends on the file pointed to by the pointy end of the arrow.
The dependencies in the above diagram follow the dependency arrows in the Clean Architecture diagram.
This project is a Koa web server app. Koa is a framework and the entry point of Koa program loads the Controllers first.
The Controllers load the Adapters, then it loads the Use Cases, then finally the Entities. Each lower stage depends on the stage above it.
Dependency Injection is used heavily to pass dependencies to the individual libraries.
Encapsulation pattern is used for unit tests.
Moving forward, I plan to use this design pattern in all my code. I spent a couple weeks refactoring the ipfs-service-provider to match these patterns and achieve 100% unit test coverage. That repository is intended to be a boilerplate for create decentralized, censorship-resistant providers of web services. I encourage all JavaScript developers to study this pattern and fork my code for their own use.
This is a fictional story about Bob and some software he set out to create. Bob is a libertarian. He loves gun culture and responsible gun ownership. He likes to drink unpasteurized milk. He's also a bachelor and would like to strike up a romantic relationship with someone in his local area.
Bob used to love the site Craigslist.org. He used to be able to trade guns, buy unpasturized milk, and peruse personal ads, but now he can’t do any of those things, because Craigslist removed them in order to comply with laws and veiled threats from the State. Bob would like to build a site just like Craigslist, but one that leverages decentralized technology, so that it doesn’t have any single point of failure for the State to shut down.
Bob is a competent software developer, but building a decentralized replacement to Craigslist is going to be a big undertaking. He doesn’t know how big, but feels pretty confident that he’s going to need help. He realizes he’s going to need to find other people like him. He needs to form a community that cares about the same thing he cares about.
Bob discovers the Permissionless Software Foundation, the PSF token, and the token-liquidity app that pegs the PSF token to BCH. He creates his own SLP token. Since he’s making a project for decentralized ads, he calls it the DAD token for Decentralized ADs.
Bob saw the crazy growth around the Spice token and other tipping tokens. He thinks that having a tipping token would be a great way to grow a community around his software idea. But he wants his token to have some kind of financial value, so that people take it seriously. He’s also fond of the PSF community and wants his token and community to be attached to this larger, like-minded community.
Bob decides to fork the token-liquidity app and use it to peg his DAD token to the PSF token with it. He’s talked to several members of the PSF that want to support his idea. They are willing to collectively stake $1,000 worth of PSF tokens to help him launch his idea. Armed with a seed fund of PSF tokens and a fork of the token-liquidity app, he adjusts the equations so that the initial value of his DAD token is $0.01 per token.
Bob is really happy with this setup. His token has a low price and low transaction fees, which makes it work great as a tipping token. It’s also loosely pegged to the PSF token, which means his project is financially connected to the bigger PSF community and even bigger cryptocurrency community. But the peg is pretty loose, so Bob and any other contributors have the potential to realize a lot of upside if their project is successful.
Bob goes about coding up his idea. He spends weeks working on it and gets a clunky proof-of-concept app up. He shows it off to the PSF community and talks about it to other cryptocurrency developers whenever he gets the chance.
Through these efforts, Alice learns about Bob’s project. She has her own reasons for wanting a decentralized clone of Craigslist, and starts contributing code to the DAD project, which benefits her own goals with the software. Bob is really happy to get high-quality code contributions from Alice. He tips her in the DAD token every time he merges a pull request. There is no formal agreement. Alice isn’t contributing code with the expectation of being paid. Bob is just tipping whatever he feels is appropriate, based on his own perceived value and what he thinks the project can afford.
Time goes on. Because of the partnership between the DAD project and PSF, the communities grow together. More developers like Alice join the project. Eventually the project improves the software to a point where it has a steady stream of users. Whenever a user places an advertisement on the platform, they pay some BCH, which goes to burn DAD tokens.
Bob runs his own site using the DAD technology, focusing on guns, unpasturized milk, and personal ads in his own state. Alice runs her own site using DAD technology, which focuses on trading cryptocurrencies. Other people run their own web apps leveraging the DAD technology, but they all have the DAD project in common.
The price of the DAD token starts to increase. At some point Bob starts to worry about the amount of money behind the token, and is concerned that he’s the only person holding the minting baton for making more DAD tokens. He reaches out to the PSF for help. The PSF helps him move the minting baton to a multisignature wallet, so that minting new tokens requires agreement of three-of-five of the top contributors to the DAD project. They also set up a multisignature ‘war-chest’ wallet to protect excess funds, so that all of the DAD project funds are not only in their token-liquidity app.
Bob feels a lot better. He’s found a way to share responsibility and liability with other top contributors that he’s built trust with. If the State decides to pick on Bob, or he needs to leave the project, the DAD project and its funds are safe.
More time goes on. Bob needs to step away from the project for personal reasons. He’s still happy to participate in the community, but he needs to significantly reduce the amount of time he spends on the project. Alice is still making great commits to the project, and agrees to take on the title of ‘maintainer’. The title isn’t too important because all funds are protected by multisignature wallets. If Alice ever needs to step away from the project too, she can easily pass on the ‘maintainer’ title to the next best contributor.
There is a steady stream of new improvements to the project, but certain areas are lacking, like dev-ops, unit tests, and documentation. These areas of work are tedious, and not nearly as fun as developing new features. Alice and Bob agree to focus their time on creating bounties to shore up the areas of the project that need more attention. They create tightly-scope code-bounties with the intention of generating small, easily-reviewable pull requests. Each bounty is tagged with a reward of DAD tokens. Alice and Bob share responsibility for creating new code-bounties and doing code reviews. They agree that whoever takes on the management and merging of a bounty gets 20% of the bounty in DAD tokens, to make it worth their time.
More time goes by. The individual contributions of Alice and Bob are less and less important to the DAD project as a whole. They've each realized significant upside from their contributions, and can take pride in making the world a better place. The DAD project takes on a life of its own. It has it’s own management of top-contributors, who direct the DAD token to balance intrinsic contributions to the code base with extrinsically motivated work on automated testing, reliability, and documentation.
In the Open Source software community, it's become common to collectively refer to a code repository, the developers working with the code, and the users consuming that code as a 'Project'. A 'Project' is not any one of those things in isolation, but the collection of them together. The Node.js Project. The Linux Project. The Mocha testing framework. The Babel transpiler. These are all examples of open source projects.
A Foundation, like the OpenJS Foundation or Apache Foundation, collect and steward Projects. This is the same role that the PSF has been playing.
A Product, without any reference to open source, is pretty widely understood. It belongs to a company and there is branding and other business considerations attached to it. Understanding the intersection of a Product and an open source Project is a puzzle that has fascinated and dogged me for years. Is there a bright line separating the concepts or do they amorphously bleed into one another? What is the 'proper' way to balance these ideas or blend them together?
My last blog post started to explore this idea in earnest. I've started to mentally unwrap the tangle of concepts that make up the PSF, FullStack.cash, and other ideas community members of the PSF have about the organization. Building a Business on Open Source greatly clarified my thinking around these topics. I've continued to have conversations with PSF members and experienced thought-leaders like Mikeal Rogers.
This blog post captures some of my latest ideas on Open Source Products vs Projects, and how these ideas relate to the Permissionless Software Foundation.
Over the course of continuously asking myself the question 'What makes up a Product vs Project?', I collected characteristics that distinguish one concept from the other. This comparison and contrast has helped me grasp the nature of the relationship between the two concepts:
Products:
Die when the company behind them dies.
Can have a brand built around them.
May have a scope, but that scope is less important than product-market fit and pivoting to meet user needs.
When a product needs specialized knowledge to take the next step in its evolution, money and people go into action to fill those gaps.
Products are primarily developed through Extrinsic motivation.
A product focuses on serving specific end-user needs.
Projects:
Never die. They simply go into hibernation until a new maintainer picks them back up or forks the project.
Branding is confusing and does not work very well, because there is no hard accountability (like a product has).
Has a clearly defined scope.
When a project needs specialized knowledge, it suffers until/unless someone with the right knowledge starts to participate.
Projects are primarily developed through Intrinsic motivation.
A project focuses on serving broad-based industry/infrastructure needs.
Companies build Products (downstream) and regularly pull down updates from the Project (upstream).
They also feed improvements back upstream to the Project, through Pull Requests and patches.
Through that relationship, both parties are better off. Since they are playing two distinct roles, the relationship is win-win and there is no conflict of interest.
Recent discussions I've had with PSF membership and industry advisors have inspired me to draw out some diagrams of what these relationships between a Project and a Product could look like. I use the PSF as an example here, but these ideas are only intended to foster discussion. They are not a proposal for the future.
The lens through which I'm viewing a lot of these lessons around Product vs Projects is the relationship between the PSF, FullStack.cash, and private companies that will join the community. Like the Linux Foundation, the PSF is intended to be made up of a consortium of complimentary businesses. Some ideas on the table for other complimentary businesses are:
A 'Code School' to help developers gain cryptocurrency experience and achieve standardized certifications.
An engineering-for-hire company that could help to match developers and entrepreneurs, and then manage the resulting projects.
A non-profit organization for custodying keys and managing the token liquidity app. A sort of 'firewall' between the PSF community and any required legal compliance.
Underpinning all these organizations is the PSF, which focuses on its custodianship and maintenance of code, code which all these organizations depend on. If the businesses behind a Product can be analogized as a building, the PSF would be the slab of concrete they are all built on top of. The dependencies could be visualized like this:
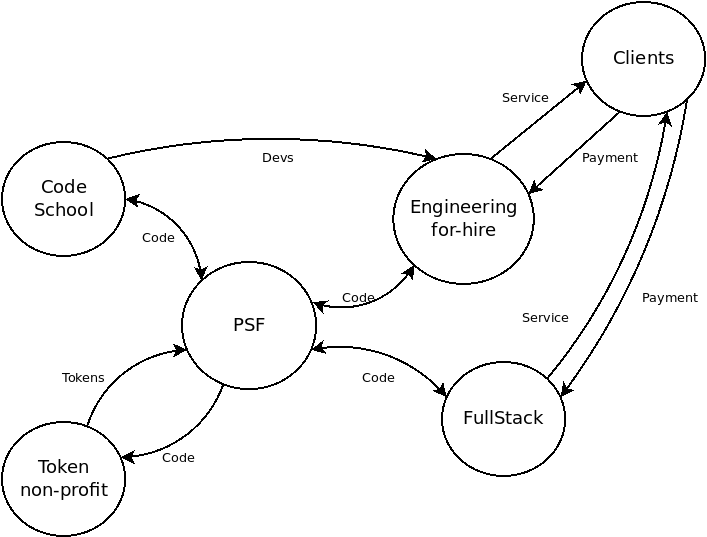
That image above depicts the dependencies, clearly showing that all the businesses depend on the PSF and share it in common. The dependencies are simple and straightforward. However, that image does not capture the nature of the relationships between the entities. That's not so simple, but equally important.
The image above captures the flow of value and the nature of the relationships between the consortium entities.
In the image above, PSF is a Foundation, which stewards code, much like the OpenJS Foundation stewards the Node.js project. The PSF would maintain the same governance structure it has now. The PSF Core software would be considered the primary project under the stewardship of the PSF, but also, only one of the projects under its care.
In this view, FullStack.cash is a business with an open source Product, which exchanges code with the PSF Core Project as described in Building a Business on Open Source. FullStack.cash services external clients and receives payment for that service. This means FullStack.cash would be a for-profit company and its current model of burning PSF tokens would need to change. More on that later.
A Non-profit corporation for working with tokens would be created, and it would have a closed-loop relationship with the PSF. This organization would focus on custody of keys for minting batons and managing token-focused software like the token-liquidity app and cross-chain token bridges. They would mint and distribute tokens according to the direction of the PSF. It's primary reason for existence is to attempt to be compliant with laws around token creation and management. (At this point in history, I believe actual compliance is impossible due to opaque guidance and over-reaching jurisdictional enforcement, but I'm no lawyer, and this entity could exist to navigate those waters as best as it can.)
An engineering-for-hire company could be formed to cater to the ever-present market demand for talented cryptocurrency developers. Importantly, this companies fate would not be tied to the PSF. It's success or failure would not necessarily reflect on the PSF or its projects, though there would be a steady flow of communication around code. There could also be many engineering-for-hire companies associated with the PSF.
Another clear market need that should be serviced is a 'code school' that can help serious cryptocurrency developers distinguish themselves against the background noise of scams and hype. Such a business, with a close relationship to the PSF, could generate great branding. It would have a natural symbiotic relationship with the PSF and the engineering-for-hire companies. There are various business models around coding bootcamps that could be applied to this organization, and fit nicely given a relationship with the engineering-for-hire company.
The diagram of relationships resembles a constellation of Products revolving around the PSF at its center. The relationships between Products is loosely coupled, but they all share the gravity of the PSF in common.
The above architecture of relationships have an impact on the token economics of the PSF. Each company and Product has a dependency on a Project stewarded by the PSF, and they are not required to have a direct relationship with the PSF token. Instead, their relationship switches to a model similar to the Linux Foundation: the companies relationship with the token would be purely for supplying financial support to the PSF (donations) and to influence the governance of the Project (by gaining the right speak in the VIP room).
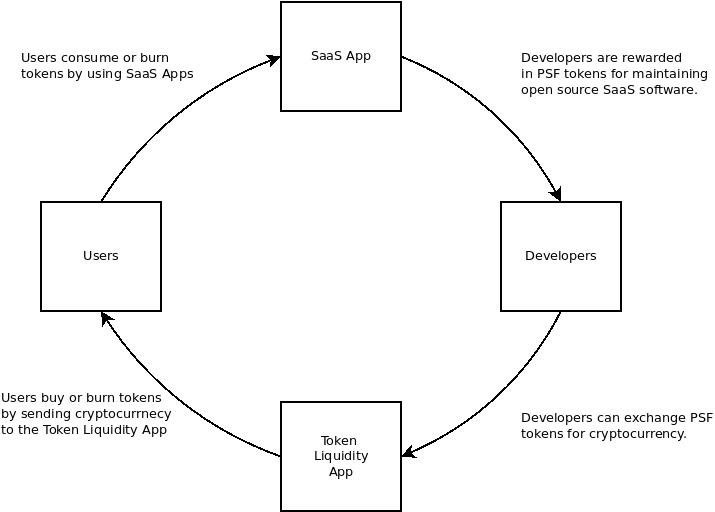
This means that the Products in the diagram are not included in the circular economy depicted below. That's a bit of a sacred cow for me, as that idea of a circular economy was largely the inspiration for the creation of the PSF. But perhaps its time for that sacred cow to evolve.
I still believe that a self-funding, circular economy using tokens is still possible. Where:
Developers maintaining software are rewarded in tokens.
Usage of software burns tokens, making the tokens held by developers more valuable.
Continuous improvement drives increased usage of the software. This improvement comes from two sources:
Intrinsically motivated development will add new features that spur growth.
Extrinsically motivated development will prevent code-rot and increase reliability.
This idea is not necessarily something that the PSF needs to stop focusing on. The PSF as a Foundation can still develop code like the pay-to-write database project, which is perfectly aligned with the above diagram.
This is an important nuance in the scope of the work done by PSF. I imagine the community will need to be careful about how it categorizes the code under its stewardship. It will need to view each code repository through the lens of the token economy:
Much of the software that is used commercially, and does not fit the closed-loop token economy, will expect donations to power the development and maintain the software.
The few software repositories that do fit well withing the closed-loop economy model, can self-fund the extrinsically motivated work to improve their code.
Maintenance and reliability are two valuable considerations for any software project. Any desire to improve these metrics require funds to pay for necessary extrinsic motivation, as intrinsic motivation is hard to come by for these two areas. Documentation is often another area where intrinsic motivation is ineffective too.
The closed-loop framework provides a self-funding mechanism for bootstrapping a project from purely intrinsic activity, to generate funds for the necessary extrinsic motivation. If this model is not viable, then donations is the only viable funding mechanism that I can see.
If I'm right in this conclusion, it will be critically important to categorize and segregate the software repositories based on how they fit within the close-loop token economy. Am I right in drawing that conclusion? That's the discussion I'm looking to have.